The UK government has been consulting on changing copyright rules to allow copying of creative works by AI companies.
We have responded to the consultation, arguing – like many – that creators’ rights must be respected.
Over the last year we have directly experienced the problems caused by AI bots.
Our Photomap contains almost 150,000 images, taken by local cyclists, providing an unparalleled resource of cycling/transport-related imagery, all geolocated and with rich metadata and categorisation.
These photos represent the hard work of our site users, who have uploaded them to demonstrate cycle/road infrastructure in areas they cycle – using this to demonstrate things that perhaps they would like to see fixed, or showing how good ideas could be transferred elsewhere.
As such, this material forms potential AI training material. That is the process of AI companies copying, or ‘scraping’ a website like ours to make a copy of the material, which they then use as raw material.
In the last 12 months, we have seen an explosion of illicit scraping activity. We have had to take increasingly extreme measures to protect the intellectual property of our users from this theft. We have seen sustained bot scraping with hundreds, even over 1,000, concurrent requests, aiming to copy our database.
This is the reality of AI scraping.
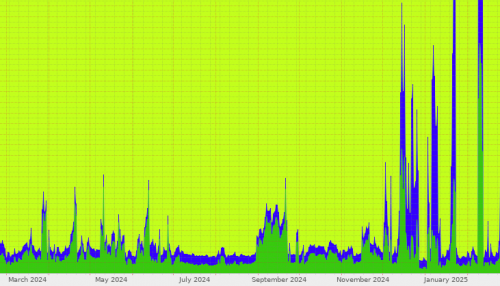
Our usage policy and our robots.txt file explicitly deny scraping for generative AI purposes, yet it is happening constantly from illicit operators. These bots almost always do not identify themselves, using vast numbers of randomised IP address from residential proxies, and using faked user-agents. As such, this is purely illicit activity. No legitimate AI company would act in this way (legitimate bots are broadly obeying our robots.txt).
These are companies copying our database without payment, creating costs which we have to bear, and in extremis denying access to legitimate visitors to our site.
These bots are not only copying our users’ images for use without attribution, they are also stealing our Database Right on an unlicensed basis. Database rights cover the overarching collection of objects in a database (in our case photographs) as distinct from the items themselves. Database rights recognise the extensive costs we (CycleStreets) have borne over many years to provide, host and facilitate, the ability to host photos.
Dealing with controlling this nuisance has also been a huge distraction from productive work, like the design changes and user-interface simplifications we are gradually rolling out around the site.
The current AI crawler bot theft situation has also highlighted the inadequacy of the robots.txt technical standard. We believe a next-generation standard to replace robots.txt is urgently needed, where allowance/denial of bot activity is determined by purpose rather than identity. We have no problem with traditional search engines. By contrast, unlicensed use by AI provides no benefit to our users or ourselves – it creates only costs.
Our response to the government consultation therefore expresses our view that:
- Copyright should not be weakened and should retain resting with the rights-holder.
- There is nothing to stop AI companies approaching rights-holders / those holding a database right (like ourselves) to request licensed use.
- We encourage innovation in the licensing space to facilitate automated bot agreement to licensing and associated payments.
- Robots.txt needs to be replaced with a next-generation, modern, JSON-based standard that provides support for limitation on the basis of usage rather than identity.
- AI bots must be required to publish their IP ranges.
- AI bots must be required to use identifiable User-Agent strings.
We have signed the Statement on AI training, and encourage others to do so. Thanks to Ed Newton-Rex and others who have worked hard on this issue.
Please do contact your MP to raise these issues, and do kindly point them to this post.